用python3.7 + sklearn实现的k-svd代码如下:
import numpy as np
from sklearn import linear_model
from sklearn.linear_model import OrthogonalMatchingPursuit as OMP
import cv2
import random
from sklearn.linear_model import orthogonal_mp
def sp_noise(image,prob):
'''
添加椒盐噪声
prob:噪声比例
'''
output = np.zeros(image.shape,np.uint8)
thres = 1 - prob
for i in range(image.shape[0]):
for j in range(image.shape[1]):
rdn = random.random()
if rdn < prob:
output[i][j] = 0
elif rdn > thres:
output[i][j] = 255
else:
output[i][j] = image[i][j]
return output
class KSVD:
def __init__(self,Y,T = 30,n_components = 256,tol=1e-6,n_nonzero_coefs=None):
'''
:param Y: 训练样本矩阵
:param T: 迭代次数
:param n_components: 字典所含原子个数
:param tol: 稀疏表示结果的容差
:param n_nonzero_coefs: 稀疏度
'''
self.Y = Y
self.D = None
self.X = None
self.T = T
self.n_components = n_components
self.tol = tol
self.n_nonzero_coefs = n_nonzero_coefs
def _initialize(self, y):
"""
用随机二阶单位范数初始化字典矩阵
"""
shape=[64,self.n_components]
#对每一列归一化为L2-norm
self.D = np.random.random(shape)
for i in range(shape[1]):
self.D[:, i]=self.D[:, i]/np.linalg.norm(self.D[:, i])
def toEk(self,k):#生成Ek
Ek = np.zeros(self.Y.shape)
M,K = self.X.shape
N = self.Y.shape[0]
for i in range(M):
if i!=k:
di = self.D[:,i].reshape(N,1)#取D第i列
xiT = self.X[i].reshape(1,K)#取X第i行
Ek = Ek + np.dot(di,xiT)
Ek = self.Y - Ek
return Ek
def toOMG(self,xk):
K = xk.shape[0]
wk = []
for i in range(K):
if xk[i] != 0:
wk.append(i)
OMG = np.zeros((K,len(wk)))
for i in range(len(wk)):
OMG[wk[i],i] = 1
return OMG
def myOMP(self):
'''
k = self.Y.shape[1]
for i in range(k):
yi = self.Y[:,i]
omp = OMP(n_nonzero_coefs=self.K)
omp.fit(self.D,yi)
self.X[:,i] = omp.predict(self[:,i])
'''
self.X = linear_model.orthogonal_mp(self.D, self.Y,n_nonzero_coefs=self.n_nonzero_coefs)
def dicUpdate(self):
self.myOMP()
M,K = self.X.shape
N = self.Y.shape[0]
for k in range(M):
dk = self.D[:, k].reshape(N, 1) # 取D第i列
x = self.X[k]
xkT = self.X[k].reshape(1, K)
Ek = self.toEk(k)
index = np.nonzero(x)[0]
if np.all(x == 0):
continue
else:
#OMG = self.toOMG(self.X[k])
#Eko = Ek.dot(OMG)
Ekr = Ek[:,index]
U,S,VT = np.linalg.svd(Ekr)
self.D[:,k] = U[:,0]
self.X[k,index] = S[0] * VT[0, :]
print(k)
def K_svd(self):
for i in range(self.T):
self.myOMP()
e = np.linalg.norm(self.Y - np.dot(self.D, self.X))
if e <= self.tol:
break
self.dicUpdate()
print(i)
def pretreatment(self,train,shape):#输入训练图像长和宽
patchnum_c = shape[0]//8 #列方向8*8 patch个数
patchnum_r = shape[1]//8 #行方向8*8 patch个数
patchnum_all = patchnum_r*patchnum_c
train = cv2.resize(train,shape,train)#将train的尺寸变为输入尺寸
img_reshape = np.zeros((64,patchnum_all),dtype='double')#保存未归一化的变换后图像
y = np.zeros((64,patchnum_all),dtype='double') #保存归一化后的图像
for i in range(patchnum_all):
r = (i//patchnum_r)*8 #当前patch的左上角行坐标
c = (i%patchnum_r)*8 #当前patch的左上角列坐标
patch = train[r:r+8,c:c+8].flatten()
#trat = train[:,0]
#patch = np.array([n for a in patch for n in a])
normalize = np.linalg.norm(patch)#求patch l2范数
mean = np.sum(patch)/64
img_reshape[:, i] = patch
# y[:, patch_index]=(patch/mean)
y[:, i] = (patch - mean * np.ones(64)) / normalize
return img_reshape,y
def fit(self,shape):#shape是指训练图像的尺寸(长和宽必须是8的倍数,如256*256)
#将输入的训练图像进行预处理,按行列分解为8*8的patch,并转换为列向量
train = self.Y
img_reshape,y = self.pretreatment(train,shape)
#初始化字典D
self._initialize(y)
self.Y = y
print("初始化完成")
self.K_svd()
def missing_pixel_reconstruct(self, img):
img_patchs=img_to_patch(img)
patch_num=img_patchs.shape[1]
#patch_dim=img_patchs.shape[0]
for i in range(patch_num):
img_col=img_patchs[:, i]
index = np.nonzero(img_col)[0]
#对每列去掉丢失的像素值后求平均、二阶范数,将其归一化
l2norm=np.linalg.norm(img_col[index])
mean=np.sum(img_col)/index.shape[0]
img_col_norm=(img_col-mean)/l2norm
x = linear_model.orthogonal_mp(self.D[index, :], img_col_norm[index].T, n_nonzero_coefs=self.n_nonzero_coefs)
img_patchs[:, i]=(self.D.dot(x)*l2norm)+mean
return patch_to_img(img_patchs)
def pixel_miss(ori,per=0.3):
img=ori.copy()
shape=img.shape
#rand=np.random.random(shape)
n=int(per*shape[0]*shape[1])
for i in range(n):
rand_r=int(np.random.random()*shape[0])
rand_c=int(np.random.random()*shape[1])
img[rand_r, rand_c]=0
return img
#将8*8块为列向量的矩阵还原为原矩阵
def patch_to_img(patchs):
patch_num=patchs.shape[1]
size=np.sqrt(patch_num).astype(np.int)
patch_size=np.sqrt(patchs.shape[0]).astype(np.int)
img=np.zeros((patch_size*size, patch_size*size))
for i in range(patch_num):
r=(i//size)*8
c=(i%size)*8
img[r:r+8, c:c+8]=patchs[:, i].reshape((8, 8))
return img
#将图像分割为8*8块作为列向量
def img_to_patch(img):
patchnum_c = img.shape[0] // 8 # 列方向8*8 patch个数
patchnum_r = img.shape[1] // 8 # 行方向8*8 patch个数
patchnum_all = patchnum_r * patchnum_c
patchs=np.zeros((8*8,patchnum_all))
for i in range(patchs.shape[1]):
#按先行后列,将图片分解成32*32个8*8的小块并装换为列向量
r=(i//patchnum_r)*8
c=(i%patchnum_r)*8
patch=img[r:r+8, c:c+8].flatten()
patchs[:, i]=patch
return patchs
if __name__ == '__main__':
noise = pixel_miss(img)
train = cv2.imread('assemble\\house.png',cv2.IMREAD_GRAYSCALE)
cv2.imshow("noise", noise)
cv2.imshow('house',train)
cv2.waitKey()
cv2.destroyAllWindows()
ksvd = KSVD(train,T = 30 )
print('111111')
ksvd.fit((256,256))
img_rec = ksvd.missing_pixel_reconstruct(noise)
img_rec = img_rec.astype(np.uint8)
cv2.imshow('noise',noise)
cv2.imshow('img_rec',img_rec)
cv2.waitKey()
cv2.destroyAllWindows()
print('safsa')该程序主要完成了:
1.先用一张256*256的图片Y,用k-svd字典学习算法训练字典D。
2.将要降噪的带噪声的图片输入,用训练好的字典D来将其稀疏表示,用OMP算法求出稀疏系数矩阵X。
3.用D点乘X,即为噪声图片经过降噪后的新图片。
下面是效果:

效果对比,左边是随机去掉30%像素值的原图,右边是用字典降噪的新图片。
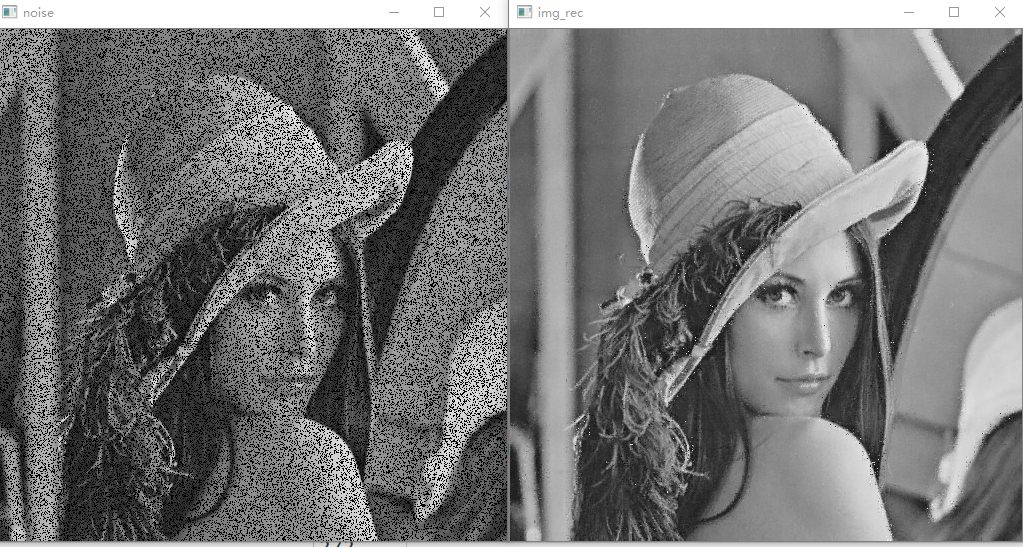
可以看出效果还是很好的。


